tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
May 9, 2017 4:17pm
three open data projects: openstreetmap, openaddresses, and who’s on first
I work in or near three major global open data collection efforts, and I’ve been asked to explain their respective goals and methods a few times in the past couple months. Each of these three projects tackles a particular slice of geospatial data, and they can be used together to build map display, search, and routing services. There are commercial products that rely on these datasets you can use right now including Mapbox Maps, Directions, and Mapzen Flex. Each data project started small and is building its way up to challenge proprietary data vendors in a familiar “slowly at first, then all at once” pattern. Each can be used as a data platform, supporting new and interesting work above.
These are some introductory notes about the three projects, please let me know in comments if I’ve missed or misrepresented something. I’m looking at four things:
- Project history
- What kind of data is inside?
- How is data licensed?
- Who uses it, and where?
OpenStreetMap - openstreetmap.org
OpenStreetMap (OSM) is an early, far-reaching open geodata project started by Steve Coast in 2004. OSM’s goal is a global street-scale map of the world, and over thirteen years it has been largely achieved. OSM data collection started in the United Kingdom around London, expanded to western Europe and the U.S., and later other countries. Initially an audacious project, OSM communicated its aims through projects such as a 2005 collaboration with Tom Carden producing a ghostly map of London made up of GPS traces collected via a courier company. OSM became convincing around 2006/07 when larger-scale imports such as U.S. Census TIGER/Line seeded whole-country coverage beyond the U.K. and Europe.
OSM data is built on user-contributed free-form tags. Over time, a core set of well-understood descriptions for common features like roads, buildings, and land use has emerged. Today, OSM boasts strong global data coverage in urban and rural areas.

An important rubric for OSM data edits is verifiability: can two people in the same place at different times agree on tags for a feature based on its appearance? There will always be debates about precise tagging schema but generally it’s possible to agree on features like residential roads, motorways, one-way streets, building footprints, parks, and rivers. Historically, OSM editors have preferred direct visits and observation of features to “armchair mapping,” a term for editing based on remotely-collected data such as satellite imagery.
OSM data has always been distributed with a license that requires attribution and share-alike. Before 2012 this was a Creative Commons (CC-BY-SA) license with copyright belonging to individual project contributors. Since 2012 the license is the Open Database License (ODbL) with copyright belonging to the OpenStreetMap Foundation (OSMF). OSMF is governed by an elected board that also holds the OSM name and trademark. ODbL requires that datasets derived from OSM also be released under the ODbL license per the share-alike clause. Many derived works such as renders or pictures of the data are not covered by the ODbL. There has long been a measure of controversy and fear, uncertainty, and doubt connected to the ODbL. OSMF publishes some guidelines about its applicability and is working on further guidance for its behavior in cases like search and geocoding. Nevertheless, major companies like Mapbox, Telenav, Apple, Uber, Mapzen (Samsung), and others have found it an acceptable license for many uses.
- OpenStreetMap Foundation homepage
- Open Database License links and information
- Open Database License Relicensing FAQ from 2012
OSM is of sufficiently high quality in populated areas to act as a display map rivaling proprietary commercial data. Thanks to its open license, mapping apps for offline use on mobile devices are a popular genre of applications for normal use. Mapbox in particular has built a substantial display mapping business on OSM data. OSM’s data quality for routing uses has also been growing, and both Mapzen and Mapbox offer commercial routing services with the data. OSM lacks certain features of proprietary routing data providers such as consistent turn restrictions and speed limits, but higher-level telemetry efforts can backfill this gap and even provide realtime traffic.
In recent years OSM has become a critical tool for international aid agencies like the Red Cross, and is often used as a reference map for disaster preparedness and response. For remote areas, organizations such as Digital Globe and Facebook are experimenting with satellite imagery feature detection techniques to improve the map, while Humanitarian OpenStreetMap Team (HOT) has provided ground mapping support and programs in locations such as Indonesia, Kibera, Haiti, Nepal, and elsewhere.
- Humanitarian OpenStreetMap Team homepage
- Facebook’s announcement of AI-assisted road tracing for OSM
- Map Kibera from 2009
- My own blog post on ca. 2016 trends in OSM editing
OpenAddresses - openaddresses.io
OpenAddresses (OA) is a relatively young project, started in 2014 by Ian Dees. OA’s goal is a complete set of global address points from authoritative sources. The first revision of OA was a spreadsheet of data sources compiled by Ian, after a suggested import of Chicago-area addresses was rejected by OpenStreetMap’s import working group. Nick Ingalls joined the project and produced the first automated code for processing OA data and began republishing aggregated collections of data. Metadata about address data sources moved from the initial spreadsheet to Github, where it was possible for a larger community of editors to use Github’s pull request workflow to add more data. I incorporated Nick’s code into a continuous integration process to make it faster and easier to contribute. Today, OA has ~460m address points around the world, with complete coverage of dozens of countries. The U.K. is notably missing, due to the privatization of Royal Mail several years back.
- First OpenAddresses spreadsheet data collection
- OpenAddresses sources on Github
- Guidelines for OA contributors
- Current OA data available for download
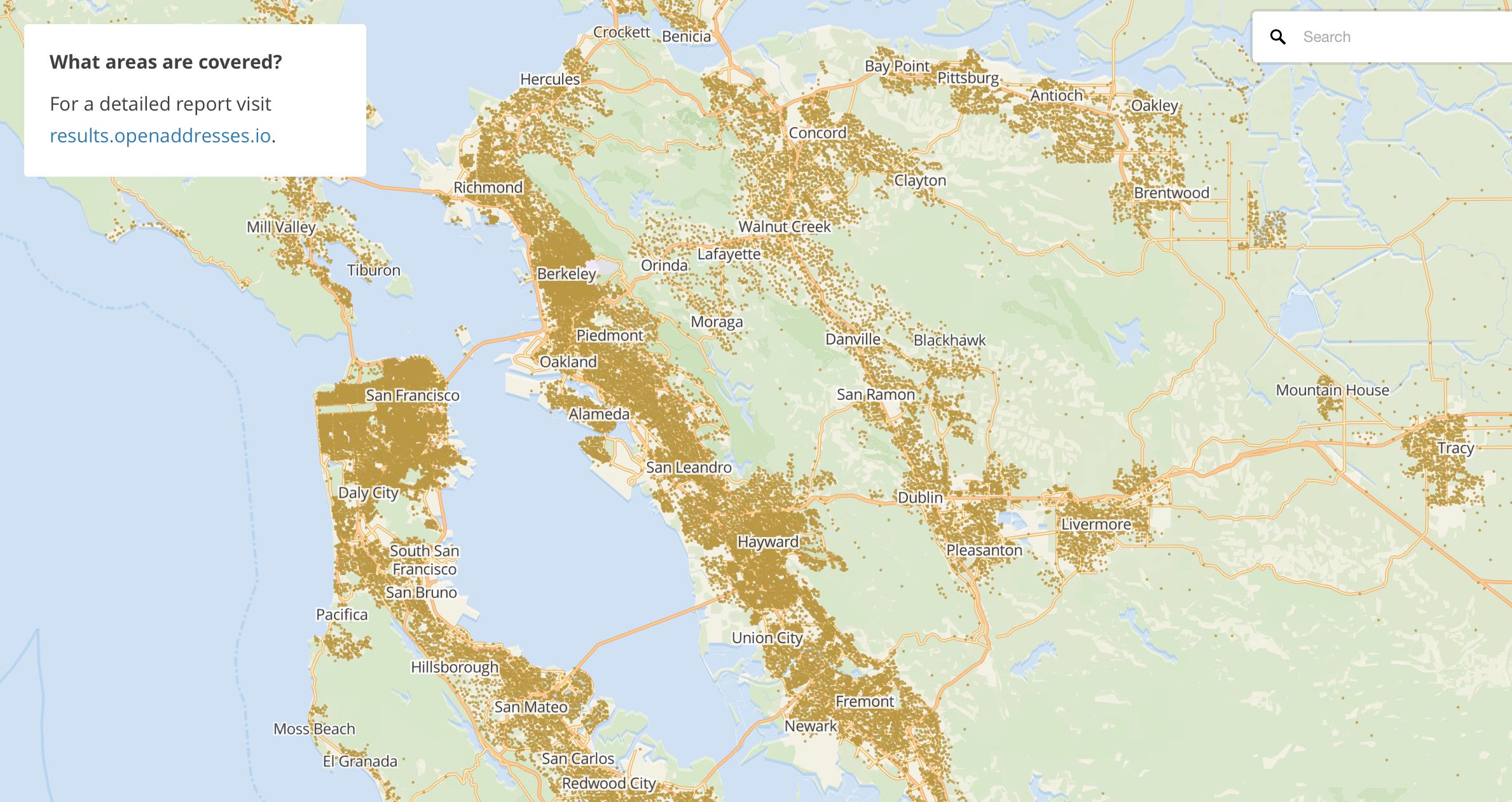
An important criteria for inclusion in OA is authoritativeness: the best datasets are sourced from local government authorities in a patchwork quilt of frequently-overlapping data. In the U.S., duplicate addresses might be sourced from city, county, and state sources. In many international cases, a single national scale data source like Australia’s GNAF provides correct, complete coverage. OA publishes point data, though points might come from a combination of rooftop, front door, and parcel centroid sources. OA’s data schema divides addresses into street number, street name, unit or apartment number, city, postcode, and administrative region. Only the street number and name are required for a valid OA data source.
OA’s JSON metadata files describing an address source are licensed under Creative Commons Zero (CC0), similar to public domain. The address data republished by OA keeps the upstream copyright information from its original sources. In some cases, sources require attribution. In a small number of cases, source license include a share-alike requirement. License features required by upstream authorities are maintained in OA metadata, and downstream users of the data are expected to use this information.
- Sample JSON metadata for addresses in Australia
- Sample JSON metadata for addresses in Alameda County, California
- Explanation of “share-alike” license requirements
OA data coverage varies worldwide, depending on open data publishing norms in each country. In the U.S., OA data covers ~80% of the population, and has been growing as small local authorities digitize and publish their address data. In some countries, complete national coverage exists at a single source. OA can be used as a piecemeal replacement for proprietary data on a country-by-country basis, or state-by-state in the United States. Mapzen’s search service uses OA data for both forward and reverse geocoding. Many OA data sources come from county tax assessor parcel databases, which may only partially reflect a full count of street addresses. It’s common for geocoders to use interpolation to fill in these spaces, with examples from Mapzen and Mapbox showing how.
Data contributors come from a variety of backgrounds. In some cases, paid contractors are working to expand OA coverage. In others, academic experts on address data seek out and describe international sources. Sometimes, a single large country import comes via a local expert.
Who’s On First - whosonfirst.mapzen.com
Who’s On First (WOF) is a gazetteer for international place and venue data started in 2015 by Aaron Cope at Mapzen, and now maintained by a data team. Data is stored as GeoJSON geometries with additional properties in numerous interconnected Github repositories. Data typically stored in WOF includes polygons for countries, administrative divisions, counties, cities, towns, postcodes, neighborhoods, and venues. WOF also accepts point data for venues and businesses. WOF properties can be very detailed, and typically feature multiple names for well-known places, such as “San Francisco,” “SF,” and even colloquial names like “Frisco.” Some WOF properties point to other datasets, such as Wikipedia or Geonames. These are called concordances, and make WOF especially useful for connecting separate data efforts. WOF geometries come in a variety of flavors, such as mainland area for San Francisco vs. the legal boundary that includes parts of the Bay and the distant Farallon Islands. Features in WOF each have a single numeric identifier, and can be connected in hierarchical relationships by way of these IDs.
- 2015 announcement of Who’s On First
- California, San Francisco, and Transamerica Building in WOF.
- Summary of WOF links to Wikipedia
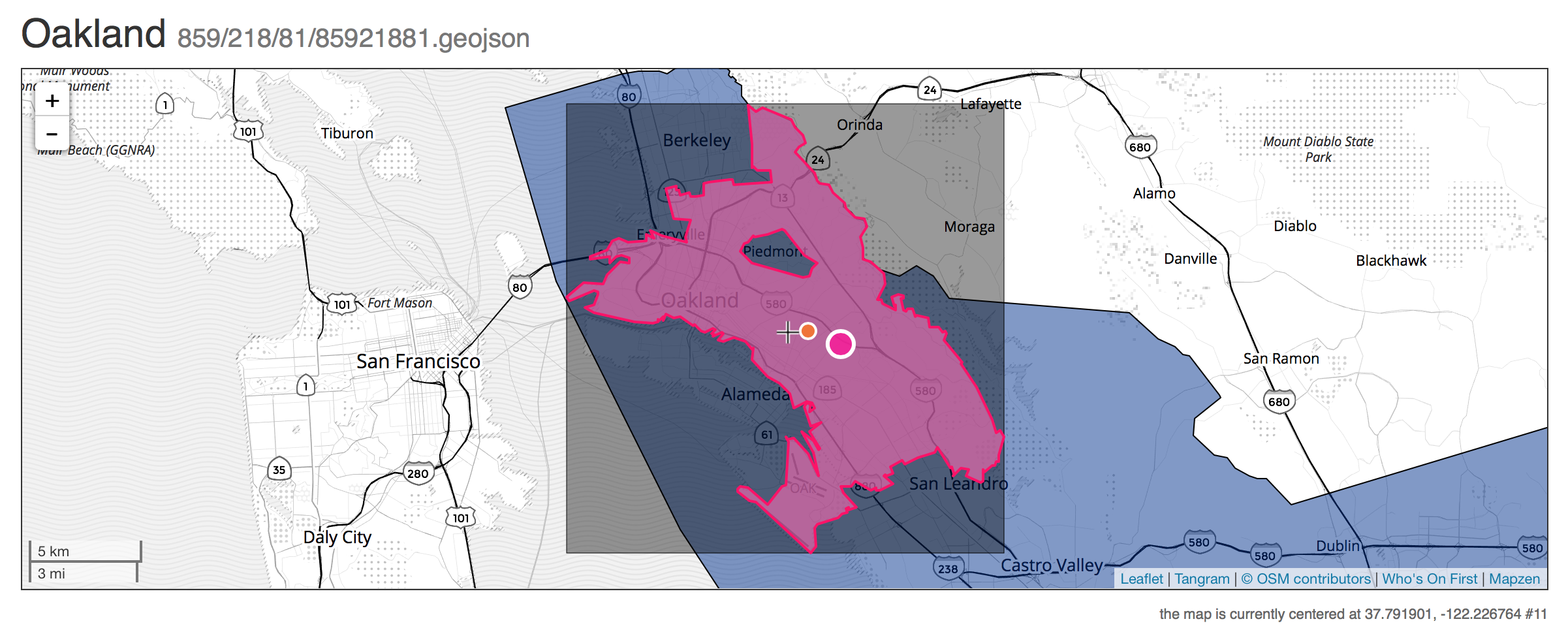
WOF data can be quite free-form, and at various times new kinds of data such as postcodes or business locations have been imported en masse. Special consideration has been paid to unique features like New York City, which spans several counties in New York and is comprised of boroughs. As a result, WOF data can be considered late binding. It’s up to a user of WOF to determine how to interpret the complete hierarchy and narrow the list of properties to a smaller set of useful ones. Five levels in the placetype hierarchy are standard: continent, country, region (like a state), locality (like a city), and neighbourhood.
WOF’s license is a combination of upstream projects under CC-BY (GeoNames and GeoPlanet), Public Domain (Natural Earth and OurAirports) and other licenses. Data quality varies due to the diversity of sources: some data comes from SimpleGeo’s 2010 data, some from Flickr- and Twitter-derived Quattroshapes, and some from official or local sources. Quality is good and WOF places generally include accurate location and size, but geometries are not necessarily suitable for visual display. Attribution is required, but no WOF data is under a share-alike license.
A major user of WOF data is Mapzen’s own search service, via the Pelias project. WOF results for venues and places are returned directly in Mapzen Search, and also used at import time to provide additional hierarchy for bare address points.
Mapzen is the primary sponsor of Who’s on First, and most data enters the project by way of Mapzen’s own staff and contractors. Contributions are governed via Github, and the many repositories under the “whosonfirst-data” organization are the authoritative sources of WOF data. The project provides downloadable bundles of data by placetype in GeoJSON format, such as as the five core hierarchy levels of continents, countries, regions, localities, and neighborhoods.
- WOF data organization in Github
- Downloadable bundles of WOF data
- Pull request template for WOF contributors
Land Of Contrast
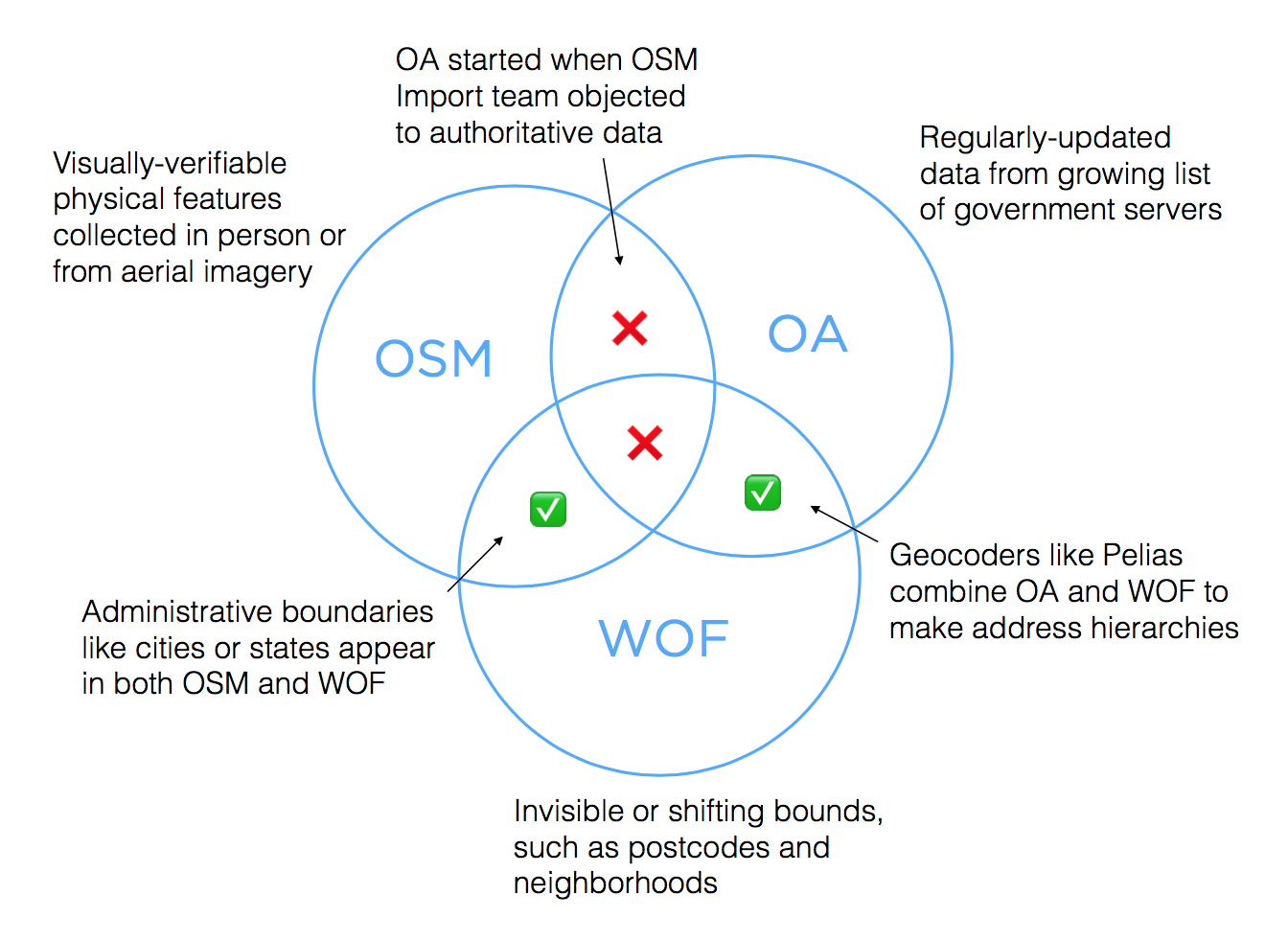
The boundaries between each of these datasets are fairly clear, with some overlaps.
- OA began when Ian Dees was unable to convince OSM’s Import group to accept Chicago addresses. Authoritative addresses can violate OSM’s verifiability heuristic, because they don’t always come with a visible house number. Authorities also update data continuously, which can be hard to reconcile after an initial one-time import to OSM. The two datasets would diverge.
- There are some addresses in OSM, typically formatted using the Karlsruhe schema. Availability varies.
- WOF includes boundaries which are often invisible, such as postcodes and neighborhoods. They are therefore hard to verify through surveys or remote mapping, making them a poor fit for OSM.
- Some easily-verifiable boundaries like city and state borders appear in both OSM and WOF, though they’re often implemented as connected linestrings in OSM and closed polygons in WOF, reflecting the uses of each data set.
- Both WOF and OA eschew OSM’s ODbL share-alike license clause, so that they can be used in tandem to run geocoders. OSMF is trying to come up with formal guidance for use with geocoders, but meanwhile it’s simpler to offer attribution-only data from WOF and OA when serving search results.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments
Sorry, no new comments on old posts.